



















こんにちは! 健史です。
COBOLではよく使われるマッチング処理について、初めてプログラミングする場合、
・2つのキーを比較しながら処理はどうやって作成するの?
・ファイルの読み込みタイミングはどうすればいいの?
・どうやって作ればわかりやすいの?
・新入社員教育でやっているけど、難しくて理解できない、困っている
という方へ、1:Nのマッチング処理を徹底解説します。
尚、プログラムはVBAで紹介・検証していますが、ロジックはCOBOLはもちろん他の言語でも使えます。
構造化によるマッチングも紹介します。
これまで「IF文によるキー比較」で作成されてこられた方も、ご一読頂ければと思います。
1:N マッチングの説明
マッチングとは、2つ以上のファイルを順次読み込み、キー項目を比較して処理することです。
「1:N マッチング」とは、商品マスタと売上ファイルのように
・商品マスタは、キーとなる商品コードに重複がなくユニーク
・売上ファイルは、キーとなる商品コードに重複がある
照合処理です。
例えば、商品コード順にソートされた商品マスタと売上ファイルがあり商品コードで照合し、
①.一致する商品コード
②.商品マスタになく、売上ファイルだけに存在する商品コード、
③.売上ファイルになく、商品マスタだけに存在する商品コード
をリストアップする場合です。
Excelであれば、2つのシートに商品マスタと売上ファイルを格納し、[VLOOKUP]関数をそれぞれの表に入力して見つけることでしょう。
データベースを操作するSQLであれば①②③とも、それぞれ数行のコマンドで抽出できるでしょう。
一部重複する部分もありますが、以下の記事に目を通して頂けますと理解しやいと思います。

2パターンのマッチング処理を紹介致します。
IF文でのマッチング
プログラムを作成するときに[IF文]でキーを比較するパターンです。
フローチャートでは横広がりになります。
フローチャート

右の[KEY1 = KEY2]のときに行う処理を
・[等しいファイルに出力]と[売上ファイル読み込み]を条件[KEY1 ≠ KEY2 になるまで]繰り返し
・[商品マスタ読み込み]の判定文を無くす
にしても同じですが、「1件づつを読み込み処理する」にするフローにしました。
ExcelVBAのプログラム
'変数を定義
Dim ix1, ix2, ixe, ixl, ixg As Long
Dim key1, key2 As String
'---------- メイン処理 ----------
Sub MAIN00()
'ファイルオープン
ix1 = 0
ix2 = 0
ixe = 0
ixl = 0
ixg = 0
Sheets(1).Columns(4).Clear
Sheets(1).Columns(5).Clear
Sheets(1).Columns(6).Clear
Sheets(1).Columns(7).Clear
Sheets(1).Columns(8).Clear
'旧商品ファイル、新商品ファイルの初期読み込み
Call SUB01_READ1
Call SUB01_READ2
'旧商品ファイル、新商品ファイルともに終了するまで繰り返す
Do Until key1 = String(1, Hex(255)) And key2 = String(1, Hex(255))
If key1 = key2 Then
Call SUB01_EQUAL
Call SUB01_READ2
If key1 <> key2 Then
Call SUB01_READ1
End If
Else
If key1 < key2 Then
Call SUB01_LESS
Call SUB01_READ1
Else
Call SUB01_GREATER
Call SUB01_READ2
End If
End If
Loop
End Sub
'---------- サブルーチン ----------
Sub SUB01_READ1()
ix1 = ix1 + 1
If Sheets(1).Cells(ix1, 1) = "" Then
key1 = String(1, Hex(255))
Else
key1 = Sheets(1).Cells(ix1, 1)
End If
End Sub
Sub SUB01_READ2()
ix2 = ix2 + 1
If Sheets(1).Cells(ix2, 2) = "" Then
key2 = String(1, Hex(255))
Else
key2 = Sheets(1).Cells(ix2, 2)
End If
End Sub
Sub SUB01_EQUAL()
ixe = ixe + 1
Sheets(1).Cells(ixe, 4) = Sheets(1).Cells(ix2, 2)
Sheets(1).Cells(ixe, 5) = Sheets(1).Cells(ix2, 3)
End Sub
Sub SUB01_LESS()
ixl = ixl + 1
Sheets(1).Cells(ixl, 6) = Sheets(1).Cells(ix1, 1)
End Sub
Sub SUB01_GREATER()
ixg = ixg + 1
Sheets(1).Cells(ixg, 7) = Sheets(1).Cells(ix2, 2)
Sheets(1).Cells(ixg, 8) = Sheets(1).Cells(ix2, 3)
End Sub
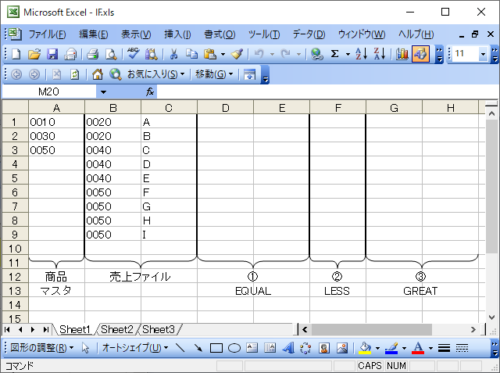
作成したデータは以下の通りです。
・処理前
・処理後
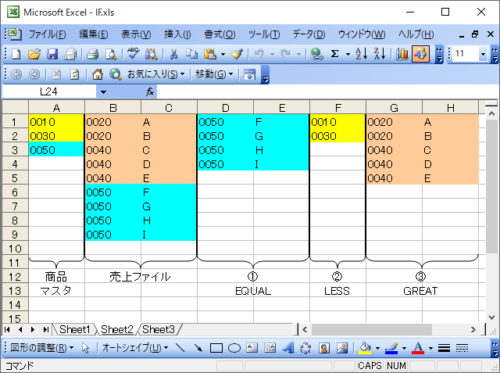
見やすくするために、すべてのファイルをSheets(1)で作成・処理しており、商品コードとしています。売上ファイルは処理前後がわかりやすいように"A",”B”など1項目を設けています。
説明を分かりやすくするために処理後の説明をsheets(2)に作成していますが、実行結果はsheets(1)に作成されます。
入力の
・[商品マスタ]はA列で、読み込みは変数ix1を1ずつアップ
・[売上ファイル]はB-C列で、読み込みは変数ix2を1ずつアップ
出力の
・①はD-E列で、書き込みは変数ixe(equalの意)を1ずつアップ
・②はF列で、書き込みは変数ixl(lessの意)を1ずつアップ
・③はG-H列で、書き込みは変数gx5(greatの意)を1ずつアップ
出力ファイルは、最初にクリアした状態にする必要があるため、[Sheets(1).Columns(n).Clear]でクリアしています。
既にオープンしているExcelシートを仮のファイルに見立てて処理していることから、
・読み書きするために必要な添え字[ix1]~[ixg]に初期値設定すること、及び、書き込むためのシートクリアをファイルオープン
・処理結果をそのまま画面に表示しおくため、ファイルのクローズ処理はない
です。
ループ処理でのマッチング
プログラムを作成するときにループで
・KEY1とKEY2が等しい間の処理を行い、等しく無くなったら次へ
・KEY1がKEY2より小さい間の処理を行い、小さく無くなったら次へ
・KEY1がKEY2より大きい間の処理を行い、大きく無くなったら先頭に戻る
で処理するパターンです。
フローチャートは縦長です。
フローチャート
以下のフローチャートは同じものです。
前者をスマホで閲覧すると鮮明ですが、パソコンでは文字が小さくなってしまうため後者を作成しました。
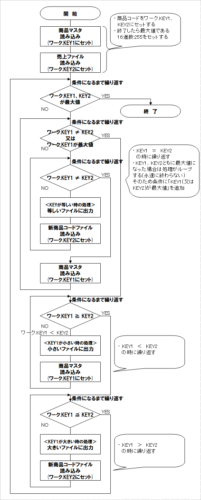

ExcelVBAのプログラム
'変数を定義
Dim ix1, ix2, ixe, ixl, ixg As Long
Dim key1, key2 As String
'---------- メイン処理 ----------
Sub MAIN00()
'ファイルオープン
ix1 = 0
ix2 = 0
ixe = 0
ixl = 0
ixg = 0
Sheets(1).Columns(4).Clear
Sheets(1).Columns(5).Clear
Sheets(1).Columns(6).Clear
Sheets(1).Columns(7).Clear
Sheets(1).Columns(8).Clear
'旧商品ファイル、新商品ファイルの初期読み込み
Call SUB01_READ1
Call SUB01_READ2
'旧商品ファイル、新商品ファイルともに終了するまで繰り返す
Do Until key1 = String(1, Hex(255)) And key2 = String(1, Hex(255))
'KEY1 = KEY2の間 繰り返す
Do Until key1 <> key2 Or key1 = String(1, Hex(255))
Do Until key1 <> key2
Call SUB01_EQUAL
Call SUB01_READ2
Loop
Call SUB01_READ1
Loop
'KEY1 < KEY2の間 繰り返す
Do Until Not (key1 < key2) '⇔ Until key1 >= key2 [≧]
Call SUB01_LESS
Call SUB01_READ1
Loop
'KEY1 > KEY2の間 繰り返す
Do Until Not (key1 > key2) '⇔ Until key1 <= key2 [≦]
Call SUB01_GREATER
Call SUB01_READ2
Loop
Loop
End Sub
'---------- サブルーチン ----------
Sub SUB01_READ1()
ix1 = ix1 + 1
If Sheets(1).Cells(ix1, 1) = "" Then
key1 = String(1, Hex(255))
Else
key1 = Sheets(1).Cells(ix1, 1)
End If
End Sub
Sub SUB01_READ2()
ix2 = ix2 + 1
If Sheets(1).Cells(ix2, 2) = "" Then
key2 = String(1, Hex(255))
Else
key2 = Sheets(1).Cells(ix2, 2)
End If
End Sub
Sub SUB01_EQUAL()
ixe = ixe + 1
Sheets(1).Cells(ixe, 4) = Sheets(1).Cells(ix2, 2)
Sheets(1).Cells(ixe, 5) = Sheets(1).Cells(ix2, 3)
End Sub
Sub SUB01_LESS()
ixl = ixl + 1
Sheets(1).Cells(ixl, 6) = Sheets(1).Cells(ix1, 1)
End Sub
Sub SUB01_GREATER()
ixg = ixg + 1
Sheets(1).Cells(ixg, 7) = Sheets(1).Cells(ix2, 2)
Sheets(1).Cells(ixg, 8) = Sheets(1).Cells(ix2, 3)
End Sub
最後に
長くなりましたが最後まで目を通して頂き、ありがとうございました!
「1:N のマッチング処理を理解できました!」でしょうか。
COBOLにてIF文型で標準化されておられる組織・担当の方、今からでもUNTIL型にすることを検討し変更されてはいかがでしょうか。
構造化できてIF文型よりは見やすく、新人の方にも説明しやすく分かりやすいと思います。
説明するときの注意点は「UNTIL条件を満たしていれば、1回も処理されない」でしょうか。[WITH TEST AFTER]をつけない限りにおいては。
尚、PL/SQLでマッチング処理を作成しました。

参考にして頂ければと思います。


コメント