


















こんにちは! 健史です。
SQLでは、マッチング処理がとても簡単にできます!
PL/SQLで同じ処理を作成してみました。
尚、入出力データはEXCELシートで説明していますが、オラクル上にロードしたデータをSqlDeveloperで実行し、正常に動作することを確認しています。
処理概要とSQLによる処理
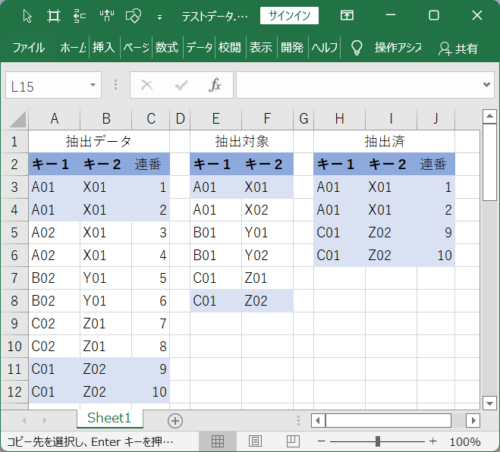
処理概要です。
テーブル[抽出データ]と[抽出対象]をKEY[キー1・キー2]で突合せ、一致するテーブル[抽出データ]を[抽出済]に出力する処理です。
SQLです。
INSERT INTO 抽出済 SELECT * FROM 抽出データ WHERE (キー1,キー2) IN (SELECT キー1,キー2 FROM 抽出対象)
副問い合わせのデータをオンコーディングした場合です。
INSERT INTO 抽出済
SELECT * FROM 抽出データ
WHERE (キー1,キー2) IN
(('A01','X01'),
('A01','X02'),
('B01','Y01'),
('B01','Y02'),
('C01','Z01'),
('C01','Z02'))
PL/SQLによる処理
プログラム
以下の記事のロジックにて作成しました。

この記事では、N:1マッチングにしてあります。
PL/SQLです。
-- <<カーソル定義>> --
CURSOR CUR1 IS
SELECT * FROM 抽出データ
ORDER BY キー1,キー2;
CURSOR CUR2 IS
SELECT * FROM 抽出対象
ORDER BY キー1,キー2;
-- <<レコード定義>> --
抽出データREC CUR1%ROWTYPE;
抽出対象REC CUR2%ROWTYPE;
抽出済REC 抽出済%ROWTYPE;
-- <<ワーク定義>> --
WK_KEY1 VARCHAR2(100);
WK_KEY2 VARCHAR2(100);
MAX_KEY VARCHAR2(100) := '゚';
-- <<ファンクション定義(サブルーチン)>> --
---- 1.テーブル1読み込み処理
FUNCTION READ1
RETURN VARCHAR2 IS
BEGIN
FETCH CUR1 INTO 抽出データREC;
IF CUR1%NOTFOUND THEN
RETURN(MAX_KEY);
ELSE
RETURN(抽出データREC.キー1||抽出データREC.キー2);
END IF;
END;
---- 2.テーブル2読み込み処理
FUNCTION READ2
RETURN VARCHAR2 IS
BEGIN
FETCH CUR2 INTO 抽出対象REC;
IF CUR2%NOTFOUND THEN
RETURN(MAX_KEY);
ELSE
RETURN(抽出対象REC.キー1||抽出対象REC.キー2);
END IF;
END;
-- <<メイン処理>> --
BEGIN
OPEN CUR1;
OPEN CUR2;
WK_KEY1 := READ1();
WK_KEY2 := READ2();
WHILE WK_KEY1 != MAX_KEY or WK_KEY2 != MAX_KEY LOOP
WHILE WK_KEY1 != MAX_KEY AND WK_KEY1 = WK_KEY2 LOOP
WHILE WK_KEY1 = WK_KEY2 LOOP
抽出済REC.キー1 := 抽出データREC.キー1;
抽出済REC.キー2 := 抽出データREC.キー2;
抽出済REC.連番 := 抽出データREC.連番;
INSERT INTO 抽出済 VALUES 抽出済REC;
WK_KEY1 := READ1();
END LOOP;
WK_KEY2 := READ2();
END LOOP;
WHILE WK_KEY1 < WK_KEY2 LOOP
WK_KEY1 := READ1();
END LOOP;
WHILE WK_KEY1 > WK_KEY2 LOOP
WK_KEY2 := READ2();
END LOOP;
END LOOP;
COMMIT;
CLOSE CUR1;
CLOSE CUR2;
補足説明
・MAX_KEYに半角の半濁音である[゚]を設定
文字が割り当てられていない最大値である16進数[FF]を使用したいのですが、COBOLであれば[HIGH-VALUE]という予約語があります。
しかしPL/SQLには[HIGH-VALUE]相当のものがありません。
そこでSJISにしてもUNICODEにしても、扱えるもので16進数としての最大値が[゚]であり使用しました。
ただし、半角の半濁音がマッチングキーの先頭に格納されているデータがある場合には、このプログラムは使用できません。
もしくは、半濁音を超える大きな値が格納されているデータがある場合にも使用できません。
・複数項目を結合した複合キーに対応
この記事では、あえて複数項目からなる値をマッチングキーにしています。
現場では単一項目によるマッチングキーは少なく、ほとんどが複合項目からなるマッチングキーです。
PL/SQLでは、[||]で項目を結合します。
結合するキー項目[WK_KEY1、WK_KEY2]は、それぞれ[VARCHAR2(100);]としています。
この記事では100桁にしていますが、結合したキー長が100桁を超える場合は変更が必要です。
また、NUMBER型の項目をマッチングキーとしてセットする場合には「LPAD」関数で頭を'0'埋めする必要があります。
文字タイプのキー2の後ろに、例えば「キー3 NUNMBER(5,0)」を連結する場合には、
RETURN(抽出データREC.キー1||抽出データREC.キー2||LPAD(抽出データREC.キー3,5,'0');
RETURN(抽出対象REC.キー1||抽出対象REC.キー2||抽出対象REC.キー3,5,'0');
とします。
これによりキー3の値が[12]の場合には[00012]に、[123]の場合には[00123]となり、正しい大小比較が可能になります。
最後に
このプログラムを作成したのは、個人的な技術検証の観点によるものです。
殆どのデータ抽出処理はSQL文で解決しますので、このマッチング処理の出番は皆無でしょう。
ですが、直接使われなくても間接的には応用できる部分があります。
他方、SQLでできることをPL/SQLで作成するマッチング処理にすると10倍以上と大変長くなり、プログラム作成の負荷が高いことは一目瞭然です。
SQLは、複雑なことが短いコマンドで簡単に実現できます。
SQLは素晴らしいです!
参考にして頂ければと思います。


コメント